

人类创造了超过7000种语言,从汉语到斯瓦希里语,从英语到纳瓦特尔语,表面上差异大到令人眼花缭乱。
但如果把这些语言的底层结构拆开来看,你会发现一件令人意外的事:它们在某些深层规律上,出奇地相似。
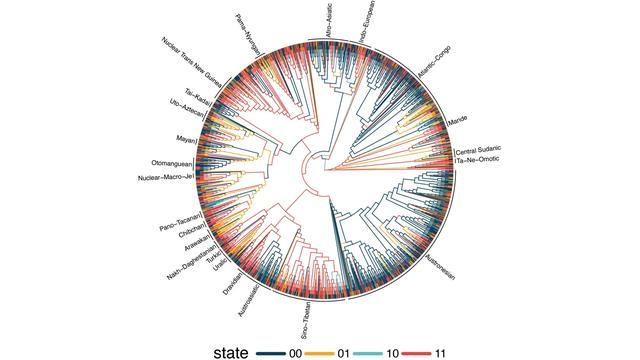
一项发表于《自然·人类行为》的最新研究,给这个几十年来争论不休的问题交出了迄今为止最严格的一份答卷。研究团队系统检验了语言学界此前提出的191条所谓"语言普遍规律",最终发现其中大约三分之一得到了强有力的统计支持。这项研究由萨尔兰大学安妮玛丽·弗克克和马克斯·普朗克进化人类学研究所罗素·格雷领导的国际团队完成,数据来源于迄今规模最大的跨语言语法数据库Grambank,覆盖了全球1705种语言。
老方法的致命漏洞,新方法从根上解决
语言普遍规律这个概念,在语言学界并不新鲜。早在上世纪60年代,语言学家约瑟夫·格林伯格就通过分析30种语言,归纳出了一批跨语言的语法共性,比如"如果一门语言的动词出现在宾语之前,那么它通常也会把介词放在名词之前"。这类规律后来被称为"格林伯格普遍规律",成为类型学研究的经典参照。
但问题一直存在。过去的研究通常采用"多样性抽样"策略,即刻意从地理上彼此远离的语言中取样,以避免亲属语言之间的相互干扰。这个方法听起来有道理,实际上却有一个致命缺陷:地理上遥远的语言未必没有共同祖先,而且这种方法无法追踪语言随时间演化的轨迹,统计结果也因此大打折扣。
这次研究团队采用的是贝叶斯空间系统发育分析方法,这是一套借鉴自进化生物学的工具,能够同时把语言的谱系关系和地理分布因素纳入统计模型。简单来说,它不只问"这两种语言像不像",还会追问"它们像,是因为有共同祖先,因为地理上相邻,还是因为独立地演化出了相同的结构"。
这种区分,正是以往研究无力做到的。
三分之一的规律,藏着人类语言的共同本能
研究结果在语言学界掀起了不小的波澜。在被检验的191条规律中,约三分之二未能通过严格的统计检验,被证明并不像此前认为的那样具有普遍性。但剩下的那三分之一,经受住了迄今最严格的方法论考验。
这些得到支持的规律,主要集中在两个方面。
一是词序偏好。比如,"主语-宾语-动词"语序的语言,倾向于把句法成分后置,也就是把修饰语放在被修饰词的后面;而"主语-动词-宾语"语序的语言,则倾向于相反的排列方式。这种词序上的系统性关联,在不相关的语言中反复独立出现。
二是语法标记的层级结构,即句子中各成分之间的关系如何通过形式手段来表达。不同语言选择了不同的表达方式,但它们在"用什么标记什么"这件事上,遵循着几乎相同的优先级逻辑。
更关键的发现在于这些规律的演化路径。祖先状态重建分析显示,在多个彼此独立的语系和地区,语言的演变轨迹反复朝向同一个方向。这不是巧合,而是一种规律性的收敛。
弗克克说:"面对巨大的语言多样性,语言的演变并非随机发生,这着实令人着迷。"格雷则将这种收敛解读为,人类共同的认知方式和交流压力,正在为所有语言的演化划定一条隐形的边界,迫使它们朝向一套数量有限的、被偏好的语法解决方案靠拢。
这项研究的意义不仅仅是确认了哪些规律成立。它更大的价值,在于用严格的方法把无效的规律筛选掉,为未来研究语言背后的认知与神经机制划定了更清晰的范围。人类为什么会说话,说话时遵循怎样的底层逻辑,这些问题的答案,或许就藏在那三分之一经受住考验的语法密码里。
倍悦网提示:文章来自网络,不代表本站观点。



